{
"cells": [
{
"cell_type": "markdown",
"id": "1e25f29b",
"metadata": {},
"source": [
"# Lecture 04. Data Aggregation and Group Operations\n",
"\n",
"### Instructor: Luping Yu\n",
"\n",
"### Mar 19, 2024\n",
"\n",
"***\n",
"\n",
"Categorizing a dataset and applying a function to each group, whether an **aggregation** or **transformation**, is often a critical component of a data analysis workflow. After loading and preparing a dataset, you may need to compute group statistics for reporting or visualization purposes.\n",
"\n",
"pandas provides a flexible groupby() interface, enabling you to slice, dice, and summarize datasets in a natural way.\n",
"\n",
"***\n",
"### GroupBy Mechanics\n",
"\n",
"Punchline: **split-apply-combine (拆分-应用-合并)** \n",
"* In the first stage of the process, data is **split** into groups based on one or more keys that you provide.\n",
"* Once this is done, a function is **applied** to each group, producing a new value.\n",
"* Finally, the results of all those function applications are **combined** into a result object.\n",
"\n",
"See the following figure for a mockup of a simple group aggregation:\n",
"\n",
"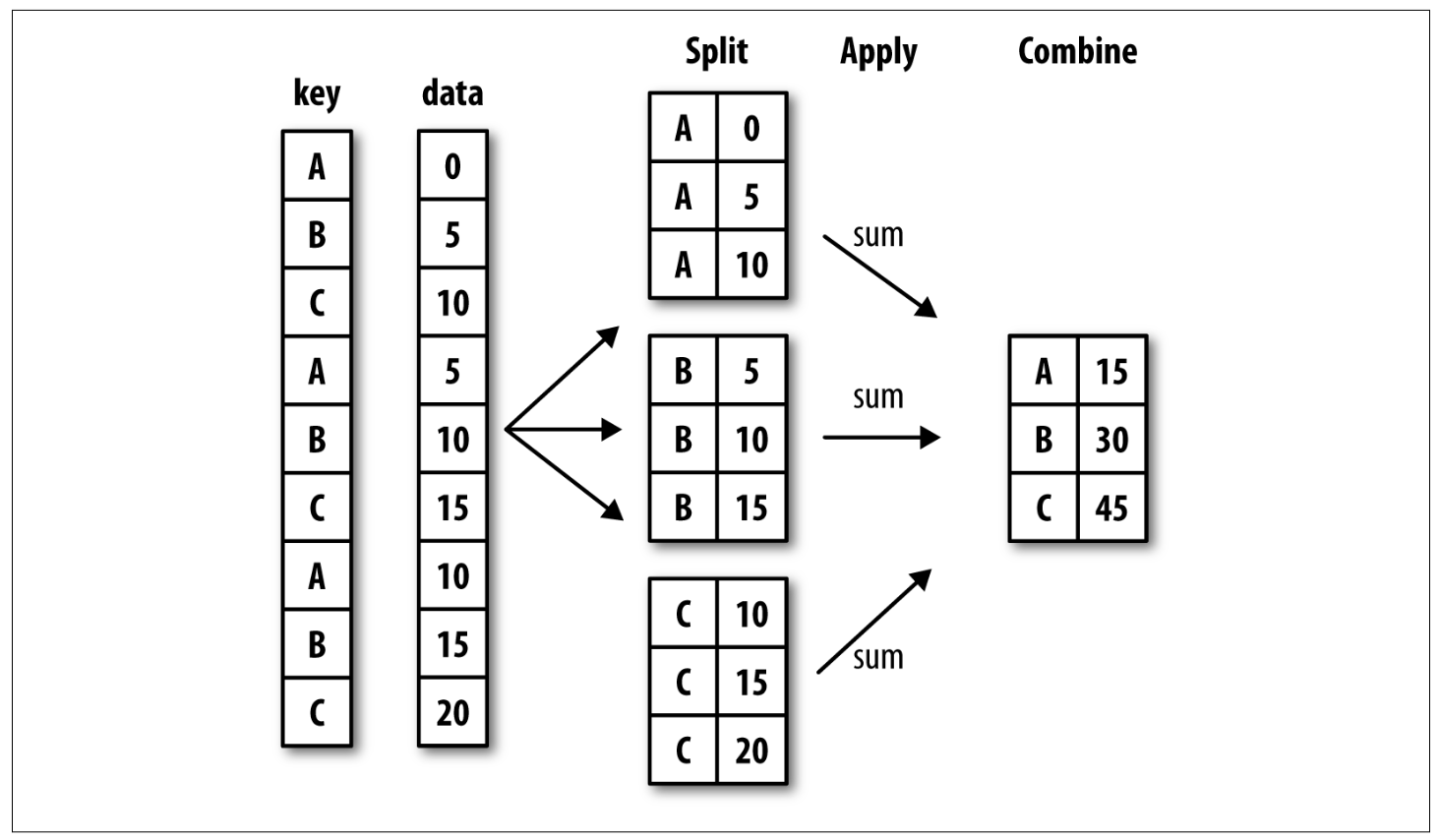\n",
"***\n",
"\n",
"To get started, here is a small tabular dataset as a DataFrame:"
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "7e30f646",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" key1 | \n",
" key2 | \n",
" data1 | \n",
" data2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" a | \n",
" one | \n",
" -1.137953 | \n",
" -1.741685 | \n",
"
\n",
" \n",
" | 1 | \n",
" a | \n",
" two | \n",
" 0.014705 | \n",
" -0.937821 | \n",
"
\n",
" \n",
" | 2 | \n",
" b | \n",
" one | \n",
" 0.140717 | \n",
" -0.420972 | \n",
"
\n",
" \n",
" | 3 | \n",
" b | \n",
" two | \n",
" -0.098441 | \n",
" 0.548059 | \n",
"
\n",
" \n",
" | 4 | \n",
" a | \n",
" one | \n",
" -1.203151 | \n",
" -0.664293 | \n",
"
\n",
" \n",
"
\n",
"
data1 column using the labels from key1.\n",
"\n",
"There are a number of ways to do this. One is to access data1 and call groupby() with the column at key1:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "4235891d",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
""
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"grouped = df['data1'].groupby(df['key1'])\n",
"\n",
"grouped"
]
},
{
"cell_type": "markdown",
"id": "42d2a5c6",
"metadata": {},
"source": [
"This grouped variable is now a GroupBy object.\n",
"\n",
"It has not actually computed anything yet except for some intermediate data about the group key df['key1']. The idea is that this object has all of the information needed to then apply some operation to each of the groups.\n",
"\n",
"For example, to compute group means we can call the GroupBy's mean() method:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "2225746f",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/plain": [
"key1\n",
"a -0.775467\n",
"b 0.021138\n",
"Name: data1, dtype: float64"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"grouped.mean()"
]
},
{
"cell_type": "markdown",
"id": "f00cb2a9",
"metadata": {},
"source": [
"The important thing here is that the data has been **aggregated** according to the group key, producing a new Series that is now indexed by the **unique values** in the key1 column.\n",
"\n",
"If instead we had passed multiple arrays as a list, we'd get something different:"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "ef277cb1",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/plain": [
"key1 key2\n",
"a one -1.170552\n",
" two 0.014705\n",
"b one 0.140717\n",
" two -0.098441\n",
"Name: data1, dtype: float64"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df['data1'].groupby([df['key1'], df['key2']]).mean()"
]
},
{
"cell_type": "markdown",
"id": "dac70643",
"metadata": {},
"source": [
"Here we grouped the data using **two keys**, and the resulting Series now has a **hierarchical index** consisting of the **unique pairs** of keys observed.\n",
"\n",
"A generally useful GroupBy method is size(), which returns a Series containing group sizes:"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "3fecc78e",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/plain": [
"key1 key2\n",
"a one 2\n",
" two 1\n",
"b one 1\n",
" two 1\n",
"dtype: int64"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df.groupby(['key1', 'key2']).size()"
]
},
{
"cell_type": "markdown",
"id": "71211471",
"metadata": {},
"source": [
"For large datasets, it may be desirable to aggregate only a few columns. For example, in the preceding dataset, to compute means for just the data2 column, we could write:"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "cffb413c",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/plain": [
"key1 key2\n",
"a one -1.202989\n",
" two -0.937821\n",
"b one -0.420972\n",
" two 0.548059\n",
"Name: data2, dtype: float64"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"df.groupby(['key1', 'key2'])['data2'].mean()"
]
},
{
"cell_type": "markdown",
"id": "c2c45ba4",
"metadata": {},
"source": [
"***\n",
"\n",
"### Data Aggregation\n",
"\n",
"**Aggregations** refer to any data transformation that produces scalar values from arrays. The preceding examples have used several of them, including mean and size. Built-in functions can be invoked using agg().\n",
"\n",
"|Function | Description |\n",
"|:- | :- | \n",
"|count | Number of non-NA values in the group\n",
"|sum | Sum of non-NA values\n",
"|mean | Mean of non-NA values\n",
"|median | Arithmetic median of non-NA values\n",
"|std, var | Unbiased (n – 1 denominator) standard deviation and variance\n",
"|min, max | Minimum and maximum of non-NA values\n",
"|first, last | First and last non-NA values\n"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "64083577",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" key1 | \n",
" data1 | \n",
" data2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" a | \n",
" -1.137953 | \n",
" -1.741685 | \n",
"
\n",
" \n",
" | 1 | \n",
" a | \n",
" 0.014705 | \n",
" -0.937821 | \n",
"
\n",
" \n",
" | 2 | \n",
" b | \n",
" 0.140717 | \n",
" -0.420972 | \n",
"
\n",
" \n",
" | 3 | \n",
" b | \n",
" -0.098441 | \n",
" 0.548059 | \n",
"
\n",
" \n",
" | 4 | \n",
" a | \n",
" -1.203151 | \n",
" -0.664293 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" data2 | \n",
"
\n",
" \n",
" | key1 | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 0.014705 | \n",
" -0.664293 | \n",
"
\n",
" \n",
" | b | \n",
" 0.140717 | \n",
" 0.548059 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" data2 | \n",
"
\n",
" \n",
" | key1 | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" -1.203151 | \n",
" -1.741685 | \n",
"
\n",
" \n",
" | b | \n",
" -0.098441 | \n",
" -0.420972 | \n",
"
\n",
" \n",
"
\n",
"
apply method:"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "778c3d27",
"metadata": {},
"outputs": [],
"source": [
"def peak_to_peak(arr):\n",
" return arr.max() - arr.min()"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "3dde8c29",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" data2 | \n",
"
\n",
" \n",
" | key1 | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 1.217856 | \n",
" 1.077392 | \n",
"
\n",
" \n",
" | b | \n",
" 0.239158 | \n",
" 0.969030 | \n",
"
\n",
" \n",
"
\n",
"
.groupby() and **built-in** functions (mean, sum, count, etc.)\n",
"* Create analysis with .groupby() and user defined functions\n",
"* Use .transform() to join group stats to the original dataframe\n",
"\n",
"Let's get started with the tipping dataset:"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "3cdb9e0b",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" day | \n",
" size | \n",
" total_bill | \n",
" tip | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Sun | \n",
" 2 | \n",
" 16.99 | \n",
" 1.01 | \n",
"
\n",
" \n",
" | 1 | \n",
" Sun | \n",
" 3 | \n",
" 10.34 | \n",
" 1.66 | \n",
"
\n",
" \n",
" | 2 | \n",
" Sun | \n",
" 3 | \n",
" 21.01 | \n",
" 3.50 | \n",
"
\n",
" \n",
" | 3 | \n",
" Sun | \n",
" 2 | \n",
" 23.68 | \n",
" 3.31 | \n",
"
\n",
" \n",
" | 4 | \n",
" Sun | \n",
" 4 | \n",
" 24.59 | \n",
" 3.61 | \n",
"
\n",
" \n",
" | ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
"
\n",
" \n",
" | 239 | \n",
" Sat | \n",
" 3 | \n",
" 29.03 | \n",
" 5.92 | \n",
"
\n",
" \n",
" | 240 | \n",
" Sat | \n",
" 2 | \n",
" 27.18 | \n",
" 2.00 | \n",
"
\n",
" \n",
" | 241 | \n",
" Sat | \n",
" 2 | \n",
" 22.67 | \n",
" 2.00 | \n",
"
\n",
" \n",
" | 242 | \n",
" Sat | \n",
" 2 | \n",
" 17.82 | \n",
" 1.75 | \n",
"
\n",
" \n",
" | 243 | \n",
" Thur | \n",
" 2 | \n",
" 18.78 | \n",
" 3.00 | \n",
"
\n",
" \n",
"
\n",
"
244 rows × 4 columns
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" size | \n",
" total_bill | \n",
" tip | \n",
"
\n",
" \n",
" | day | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | Fri | \n",
" 2.105263 | \n",
" 17.151579 | \n",
" 2.734737 | \n",
"
\n",
" \n",
" | Sat | \n",
" 2.517241 | \n",
" 20.441379 | \n",
" 2.993103 | \n",
"
\n",
" \n",
" | Sun | \n",
" 2.842105 | \n",
" 21.410000 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | Thur | \n",
" 2.451613 | \n",
" 17.682742 | \n",
" 2.771452 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" size | \n",
" total_bill | \n",
" tip | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 2.842105 | \n",
" 21.410000 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | 1 | \n",
" 2.842105 | \n",
" 21.410000 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | 2 | \n",
" 2.842105 | \n",
" 21.410000 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | 3 | \n",
" 2.842105 | \n",
" 21.410000 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | 4 | \n",
" 2.842105 | \n",
" 21.410000 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
"
\n",
" \n",
" | 239 | \n",
" 2.517241 | \n",
" 20.441379 | \n",
" 2.993103 | \n",
"
\n",
" \n",
" | 240 | \n",
" 2.517241 | \n",
" 20.441379 | \n",
" 2.993103 | \n",
"
\n",
" \n",
" | 241 | \n",
" 2.517241 | \n",
" 20.441379 | \n",
" 2.993103 | \n",
"
\n",
" \n",
" | 242 | \n",
" 2.517241 | \n",
" 20.441379 | \n",
" 2.993103 | \n",
"
\n",
" \n",
" | 243 | \n",
" 2.451613 | \n",
" 17.682742 | \n",
" 2.771452 | \n",
"
\n",
" \n",
"
\n",
"
244 rows × 3 columns
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" day | \n",
" size | \n",
" total_bill | \n",
" tip | \n",
" day_avg_tip | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Sun | \n",
" 2 | \n",
" 16.99 | \n",
" 1.01 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | 1 | \n",
" Sun | \n",
" 3 | \n",
" 10.34 | \n",
" 1.66 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | 2 | \n",
" Sun | \n",
" 3 | \n",
" 21.01 | \n",
" 3.50 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | 3 | \n",
" Sun | \n",
" 2 | \n",
" 23.68 | \n",
" 3.31 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | 4 | \n",
" Sun | \n",
" 4 | \n",
" 24.59 | \n",
" 3.61 | \n",
" 3.255132 | \n",
"
\n",
" \n",
" | ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
"
\n",
" \n",
" | 239 | \n",
" Sat | \n",
" 3 | \n",
" 29.03 | \n",
" 5.92 | \n",
" 2.993103 | \n",
"
\n",
" \n",
" | 240 | \n",
" Sat | \n",
" 2 | \n",
" 27.18 | \n",
" 2.00 | \n",
" 2.993103 | \n",
"
\n",
" \n",
" | 241 | \n",
" Sat | \n",
" 2 | \n",
" 22.67 | \n",
" 2.00 | \n",
" 2.993103 | \n",
"
\n",
" \n",
" | 242 | \n",
" Sat | \n",
" 2 | \n",
" 17.82 | \n",
" 1.75 | \n",
" 2.993103 | \n",
"
\n",
" \n",
" | 243 | \n",
" Thur | \n",
" 2 | \n",
" 18.78 | \n",
" 3.00 | \n",
" 2.771452 | \n",
"
\n",
" \n",
"
\n",
"
244 rows × 5 columns
\n",
"
mean or std.\n",
"\n",
"However, you may want to aggregate using a different function depending on the column, or multiple functions at once."
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "7a53da08",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" total_bill | \n",
" tip | \n",
" sex | \n",
" smoker | \n",
" day | \n",
" time | \n",
" size | \n",
" tip_pct | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 16.99 | \n",
" 1.01 | \n",
" Female | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 2 | \n",
" 0.059447 | \n",
"
\n",
" \n",
" | 1 | \n",
" 10.34 | \n",
" 1.66 | \n",
" Male | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 3 | \n",
" 0.160542 | \n",
"
\n",
" \n",
" | 2 | \n",
" 21.01 | \n",
" 3.50 | \n",
" Male | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 3 | \n",
" 0.166587 | \n",
"
\n",
" \n",
" | 3 | \n",
" 23.68 | \n",
" 3.31 | \n",
" Male | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 2 | \n",
" 0.139780 | \n",
"
\n",
" \n",
" | 4 | \n",
" 24.59 | \n",
" 3.61 | \n",
" Female | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 4 | \n",
" 0.146808 | \n",
"
\n",
" \n",
" | ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
"
\n",
" \n",
" | 239 | \n",
" 29.03 | \n",
" 5.92 | \n",
" Male | \n",
" No | \n",
" Sat | \n",
" Dinner | \n",
" 3 | \n",
" 0.203927 | \n",
"
\n",
" \n",
" | 240 | \n",
" 27.18 | \n",
" 2.00 | \n",
" Female | \n",
" Yes | \n",
" Sat | \n",
" Dinner | \n",
" 2 | \n",
" 0.073584 | \n",
"
\n",
" \n",
" | 241 | \n",
" 22.67 | \n",
" 2.00 | \n",
" Male | \n",
" Yes | \n",
" Sat | \n",
" Dinner | \n",
" 2 | \n",
" 0.088222 | \n",
"
\n",
" \n",
" | 242 | \n",
" 17.82 | \n",
" 1.75 | \n",
" Male | \n",
" No | \n",
" Sat | \n",
" Dinner | \n",
" 2 | \n",
" 0.098204 | \n",
"
\n",
" \n",
" | 243 | \n",
" 18.78 | \n",
" 3.00 | \n",
" Female | \n",
" No | \n",
" Thur | \n",
" Dinner | \n",
" 2 | \n",
" 0.159744 | \n",
"
\n",
" \n",
"
\n",
"
244 rows × 8 columns
\n",
"
DataFrame with column names taken from the functions:"
]
},
{
"cell_type": "code",
"execution_count": 18,
"id": "08a685d5",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" | \n",
" mean | \n",
" median | \n",
" std | \n",
"
\n",
" \n",
" | day | \n",
" smoker | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | Fri | \n",
" No | \n",
" 0.151650 | \n",
" 0.149241 | \n",
" 0.028123 | \n",
"
\n",
" \n",
" | Yes | \n",
" 0.174783 | \n",
" 0.173913 | \n",
" 0.051293 | \n",
"
\n",
" \n",
" | Sat | \n",
" No | \n",
" 0.158048 | \n",
" 0.150152 | \n",
" 0.039767 | \n",
"
\n",
" \n",
" | Yes | \n",
" 0.147906 | \n",
" 0.153624 | \n",
" 0.061375 | \n",
"
\n",
" \n",
" | Sun | \n",
" No | \n",
" 0.160113 | \n",
" 0.161665 | \n",
" 0.042347 | \n",
"
\n",
" \n",
" | Yes | \n",
" 0.187250 | \n",
" 0.138122 | \n",
" 0.154134 | \n",
"
\n",
" \n",
" | Thur | \n",
" No | \n",
" 0.160298 | \n",
" 0.153492 | \n",
" 0.038774 | \n",
"
\n",
" \n",
" | Yes | \n",
" 0.163863 | \n",
" 0.153846 | \n",
" 0.039389 | \n",
"
\n",
" \n",
"
\n",
"
apply(). Suppose you wanted to select the top five tip_pct values by group."
]
},
{
"cell_type": "code",
"execution_count": 19,
"id": "064a0de2",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" total_bill | \n",
" tip | \n",
" sex | \n",
" smoker | \n",
" day | \n",
" time | \n",
" size | \n",
" tip_pct | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 16.99 | \n",
" 1.01 | \n",
" Female | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 2 | \n",
" 0.059447 | \n",
"
\n",
" \n",
" | 1 | \n",
" 10.34 | \n",
" 1.66 | \n",
" Male | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 3 | \n",
" 0.160542 | \n",
"
\n",
" \n",
" | 2 | \n",
" 21.01 | \n",
" 3.50 | \n",
" Male | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 3 | \n",
" 0.166587 | \n",
"
\n",
" \n",
" | 3 | \n",
" 23.68 | \n",
" 3.31 | \n",
" Male | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 2 | \n",
" 0.139780 | \n",
"
\n",
" \n",
" | 4 | \n",
" 24.59 | \n",
" 3.61 | \n",
" Female | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 4 | \n",
" 0.146808 | \n",
"
\n",
" \n",
" | ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
"
\n",
" \n",
" | 239 | \n",
" 29.03 | \n",
" 5.92 | \n",
" Male | \n",
" No | \n",
" Sat | \n",
" Dinner | \n",
" 3 | \n",
" 0.203927 | \n",
"
\n",
" \n",
" | 240 | \n",
" 27.18 | \n",
" 2.00 | \n",
" Female | \n",
" Yes | \n",
" Sat | \n",
" Dinner | \n",
" 2 | \n",
" 0.073584 | \n",
"
\n",
" \n",
" | 241 | \n",
" 22.67 | \n",
" 2.00 | \n",
" Male | \n",
" Yes | \n",
" Sat | \n",
" Dinner | \n",
" 2 | \n",
" 0.088222 | \n",
"
\n",
" \n",
" | 242 | \n",
" 17.82 | \n",
" 1.75 | \n",
" Male | \n",
" No | \n",
" Sat | \n",
" Dinner | \n",
" 2 | \n",
" 0.098204 | \n",
"
\n",
" \n",
" | 243 | \n",
" 18.78 | \n",
" 3.00 | \n",
" Female | \n",
" No | \n",
" Thur | \n",
" Dinner | \n",
" 2 | \n",
" 0.159744 | \n",
"
\n",
" \n",
"
\n",
"
244 rows × 8 columns
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" total_bill | \n",
" tip | \n",
" sex | \n",
" smoker | \n",
" day | \n",
" time | \n",
" size | \n",
" tip_pct | \n",
"
\n",
" \n",
" \n",
" \n",
" | 172 | \n",
" 7.25 | \n",
" 5.15 | \n",
" Male | \n",
" Yes | \n",
" Sun | \n",
" Dinner | \n",
" 2 | \n",
" 0.710345 | \n",
"
\n",
" \n",
" | 178 | \n",
" 9.60 | \n",
" 4.00 | \n",
" Female | \n",
" Yes | \n",
" Sun | \n",
" Dinner | \n",
" 2 | \n",
" 0.416667 | \n",
"
\n",
" \n",
" | 67 | \n",
" 3.07 | \n",
" 1.00 | \n",
" Female | \n",
" Yes | \n",
" Sat | \n",
" Dinner | \n",
" 1 | \n",
" 0.325733 | \n",
"
\n",
" \n",
" | 232 | \n",
" 11.61 | \n",
" 3.39 | \n",
" Male | \n",
" No | \n",
" Sat | \n",
" Dinner | \n",
" 2 | \n",
" 0.291990 | \n",
"
\n",
" \n",
" | 183 | \n",
" 23.17 | \n",
" 6.50 | \n",
" Male | \n",
" Yes | \n",
" Sun | \n",
" Dinner | \n",
" 4 | \n",
" 0.280535 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" | \n",
" total_bill | \n",
" tip | \n",
" sex | \n",
" smoker | \n",
" day | \n",
" time | \n",
" size | \n",
" tip_pct | \n",
"
\n",
" \n",
" | sex | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | Female | \n",
" 178 | \n",
" 9.60 | \n",
" 4.00 | \n",
" Female | \n",
" Yes | \n",
" Sun | \n",
" Dinner | \n",
" 2 | \n",
" 0.416667 | \n",
"
\n",
" \n",
" | 67 | \n",
" 3.07 | \n",
" 1.00 | \n",
" Female | \n",
" Yes | \n",
" Sat | \n",
" Dinner | \n",
" 1 | \n",
" 0.325733 | \n",
"
\n",
" \n",
" | 109 | \n",
" 14.31 | \n",
" 4.00 | \n",
" Female | \n",
" Yes | \n",
" Sat | \n",
" Dinner | \n",
" 2 | \n",
" 0.279525 | \n",
"
\n",
" \n",
" | 93 | \n",
" 16.32 | \n",
" 4.30 | \n",
" Female | \n",
" Yes | \n",
" Fri | \n",
" Dinner | \n",
" 2 | \n",
" 0.263480 | \n",
"
\n",
" \n",
" | 221 | \n",
" 13.42 | \n",
" 3.48 | \n",
" Female | \n",
" Yes | \n",
" Fri | \n",
" Lunch | \n",
" 2 | \n",
" 0.259314 | \n",
"
\n",
" \n",
" | Male | \n",
" 172 | \n",
" 7.25 | \n",
" 5.15 | \n",
" Male | \n",
" Yes | \n",
" Sun | \n",
" Dinner | \n",
" 2 | \n",
" 0.710345 | \n",
"
\n",
" \n",
" | 232 | \n",
" 11.61 | \n",
" 3.39 | \n",
" Male | \n",
" No | \n",
" Sat | \n",
" Dinner | \n",
" 2 | \n",
" 0.291990 | \n",
"
\n",
" \n",
" | 183 | \n",
" 23.17 | \n",
" 6.50 | \n",
" Male | \n",
" Yes | \n",
" Sun | \n",
" Dinner | \n",
" 4 | \n",
" 0.280535 | \n",
"
\n",
" \n",
" | 149 | \n",
" 7.51 | \n",
" 2.00 | \n",
" Male | \n",
" No | \n",
" Thur | \n",
" Lunch | \n",
" 2 | \n",
" 0.266312 | \n",
"
\n",
" \n",
" | 181 | \n",
" 23.33 | \n",
" 5.65 | \n",
" Male | \n",
" Yes | \n",
" Sun | \n",
" Dinner | \n",
" 2 | \n",
" 0.242177 | \n",
"
\n",
" \n",
"
\n",
"
top function is called on each row group from the DataFrame. The result therefore has a hierarchical index whose inner level contains index values from the original DataFrame.\n",
"\n",
"If you pass a function to apply that takes other **arguments or keywords**, you can pass these after the function:"
]
},
{
"cell_type": "code",
"execution_count": 23,
"id": "9873434c",
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" | \n",
" | \n",
" total_bill | \n",
" tip | \n",
" sex | \n",
" smoker | \n",
" day | \n",
" time | \n",
" size | \n",
" tip_pct | \n",
"
\n",
" \n",
" | sex | \n",
" day | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | Female | \n",
" Fri | \n",
" 94 | \n",
" 22.75 | \n",
" 3.25 | \n",
" Female | \n",
" No | \n",
" Fri | \n",
" Dinner | \n",
" 2 | \n",
" 0.142857 | \n",
"
\n",
" \n",
" | Sat | \n",
" 102 | \n",
" 44.30 | \n",
" 2.50 | \n",
" Female | \n",
" Yes | \n",
" Sat | \n",
" Dinner | \n",
" 3 | \n",
" 0.056433 | \n",
"
\n",
" \n",
" | Sun | \n",
" 11 | \n",
" 35.26 | \n",
" 5.00 | \n",
" Female | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 4 | \n",
" 0.141804 | \n",
"
\n",
" \n",
" | Thur | \n",
" 197 | \n",
" 43.11 | \n",
" 5.00 | \n",
" Female | \n",
" Yes | \n",
" Thur | \n",
" Lunch | \n",
" 4 | \n",
" 0.115982 | \n",
"
\n",
" \n",
" | Male | \n",
" Fri | \n",
" 95 | \n",
" 40.17 | \n",
" 4.73 | \n",
" Male | \n",
" Yes | \n",
" Fri | \n",
" Dinner | \n",
" 4 | \n",
" 0.117750 | \n",
"
\n",
" \n",
" | Sat | \n",
" 170 | \n",
" 50.81 | \n",
" 10.00 | \n",
" Male | \n",
" Yes | \n",
" Sat | \n",
" Dinner | \n",
" 3 | \n",
" 0.196812 | \n",
"
\n",
" \n",
" | Sun | \n",
" 156 | \n",
" 48.17 | \n",
" 5.00 | \n",
" Male | \n",
" No | \n",
" Sun | \n",
" Dinner | \n",
" 6 | \n",
" 0.103799 | \n",
"
\n",
" \n",
" | Thur | \n",
" 142 | \n",
" 41.19 | \n",
" 5.00 | \n",
" Male | \n",
" No | \n",
" Thur | \n",
" Lunch | \n",
" 5 | \n",
" 0.121389 | \n",
"
\n",
" \n",
"
\n",
"